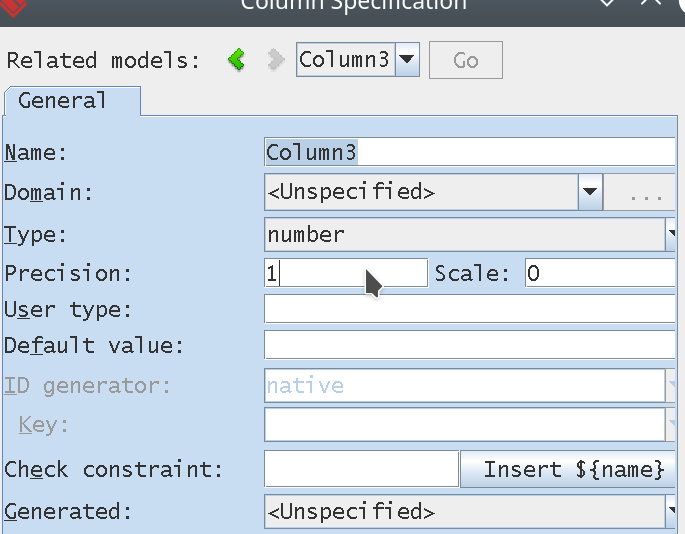
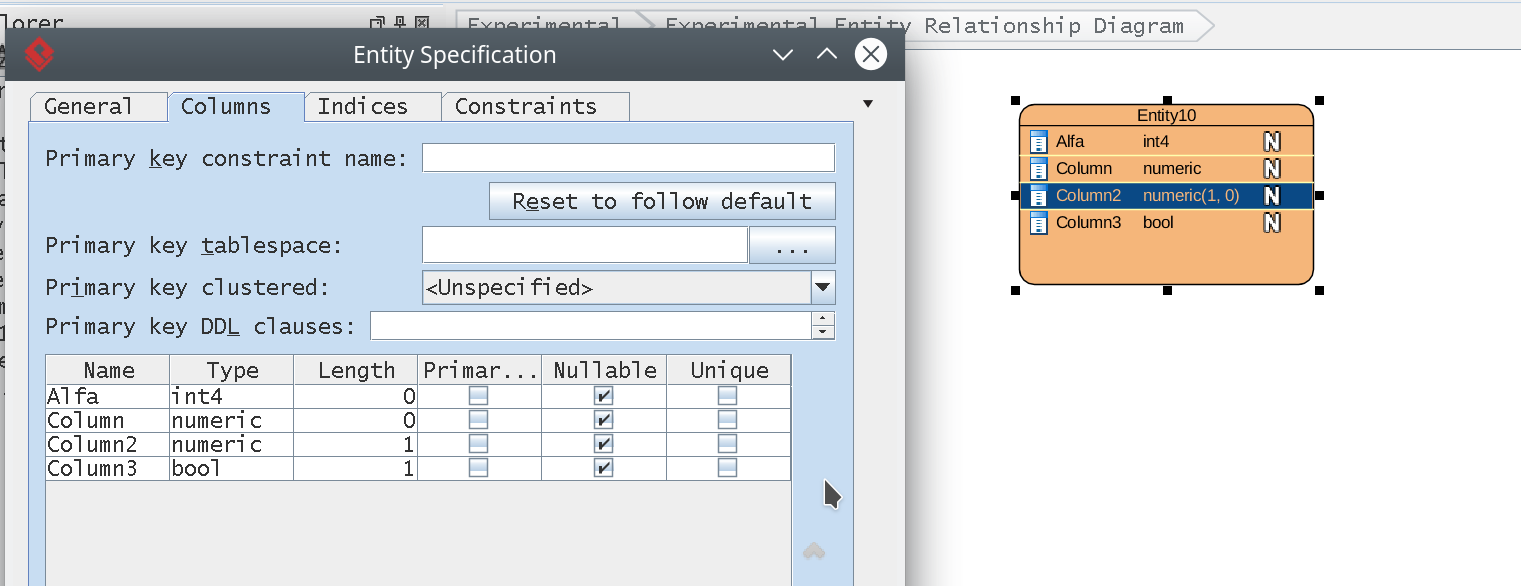
When we have in our database model Oracle column of type; NUMBER(1,0) DEFAULT 0
I reverse it back to Visual paradigm and then take from physical model Postgres DDL, but the number becomes bool. Although boolean in Postgres supports values like 0 and 1 (false and true respectively), its wrong as this must support range 0-9 to be stored in.
VP support multiple DBMS and ORM, and auto synchronize between them, so we have to map data types in each DBMS.
But there are no boolean type in Oracle, a common practice is number(1), so PostgreSQL boolean will convert to Oracle number(1) by default.
Oracle number(1) may used as boolean or digit 0-9, and there are no perfect match in PostgreSQL, boolean and smallint are potential match, and default is boolean based on above rule.
So there are no perfect rules to convert data type between different DBMS, sometimes may require manual adjustment.
I agree, data type mapping is not always straight, but as you are aware of such fact, I would expect you will provide mechanism for the user to override default mapping you provide on both global and entity/column level.
So in one table I can let number become boolean and in other table I can define conversion to be int, or simply override. Such user override mapping functionality should be provided across all database support.
ADD: For every database supported you should think about additional dimension which is the database engine version as each version supports different data types.
So you can move this to feature request as you could imagine its not usable.
SIMILAR ISSUE: Similar issue is when you convert small numbers into SERIAL which is the biggest integer in Postgres. This is causing issues also for data generators, etc. User should be in general able to override what you guys think is best as it is not best in our real use cases.
I agree that it is better to provide a global level default mapping. But there are many dimensions so it could be complex, we’ll consider if we found a better solution.
For column level, you can modify the type after switch to PostgreSQL. If you want to override a column type for specify database, you can define in “User type”.
I myself can see the complexity of such task and agree this requires some more brainstorming.
But 2 points to summarize from my side to keep in mind:
Global mapping is customisable by user
User can override it on specific column
Again we have very large data project (I mean super large) And it will be even good to think about even as placeholder temporarily something like database version as new dimension which will default to something. Maybe there can be functionality where users will submit anonymously their customized mappings. But this last point is completely far away and just idea at moment.
My situation is similar but on top I have external systems which are not supported by VP at moment:
Hive - it has different data types supported across versions (very complex)
Huawei Data Lake Insight - Hive based, but only limited specific data types
Huawei DWS - Postgres like structure, but customized by Huawei
Here VP is not helping me with my case, if I can easily create my specific product mapping within VP with column level overrides, it will be great, but at moment I export from VP DDL which I parse (yes, I have grammar parser) and convert it into specific Vendor data types.
I think I am not the only one. If someone works with cloud storage engines like AWS, Huawei or Alibaba, Google they have their own specific data types in products. You as Visual Paradigm cannot keep up with all of Vendors. By trying to keep up, you slow down the users (me), so that is the reason why I suggest introduce fully customizable data type mappings (global, column override levels) so I can come to VP and define my own mapping. See in some cases I talk about 20 data types only (Hive Huawei clone), in some its more complex like Postgres which supports super-wide variety of data types.
ThePreformatted text thing is that when I try to create a column as number (1), VP on the fly converts in the entity diagram the column to bool. But I understand VP works with NUMBERIC, not number, number(1) converts to bool, but still this is not from my perspective correct behavior.
A type mapping (simplified) for Oracle <-> PostgreSQL are:
number(1) <-> bool
number(n) <-> numeric(n)
As I explained before, Oracle number(1) can convert to PostgreSQL bool or numeric(1), but default as bool. But in the other side PostgreSQL numeric(1) must convert to Oracle number(1).
So when you’re working in PostgreSQL, you should select a PostgreSQL type numeric(1) instead of select Oracle type number(1) (will auto convert back to default db (PostgreSQL) as bool).
But this is auto-conversion which is loosing resolution on data, its not correct. representation of Oracle can be numberic(n) or char or varchar2(1) or maybe even some other, but cases:
Ora number(1) - pg bool -> you loose resolution, its not correct.
I think general idea to convert types from engine to engine should be simple:
Convert to type which is closest, but DOES NOT LOOSE RESOLUTION.
I would like to let you know our engineers deployed a new build which now support sync Oracle number(1) to the smallest integer type when changing project target DB. Please update the software to latest patch build (20190330ag or later) to get this enhancement. Details about update to latest patch can be found at
Please make sure you have pressed the “Update to latest patch” button on the left hand side of the dialog right after launching the update program
Feel free to contact me if you require any further information.
I tested today again and being on Build 20190330aw (which the patch offered to me, so I assume its another patch after ag, so my fix should be included), but when I export DDL in postgres form I still get bool.