I’m trying to figure out how to handle something like this:
try
{
block A
}
catch (Exception E)
{
block B
return
}
finally
{
block C
}
block D
I know that the UML 2.1 spec says that “the successors of an exception handler body are the same as the successors to the protected node”. The protected node here is inside the try clause, and the exception handler is inside the catch clause. So that would be great if the exception handler didn’t return or throw another exception.
The problem is, how to model the fact that the finally clause (block C) gets executed after block B, but then the flow is ended by virtue of the end of flow in the exception handler?
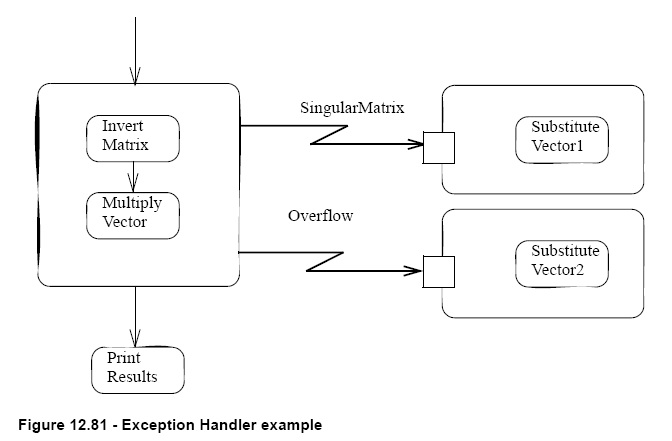
Thanks for your post. You can refer to Figure 12.81 (the image attached) in Section 12.3.23 in UML 2.1 specification, we can take “Print Results” as the “final” clause in this example.
In your case, you can take “block C” similar to the role of “Print Results”, and “block D” is something following “block C”.
If there are any further inquiries, please feel free to ask.
That diagram looks familiar, because I had already stared at it for at least an hour
My problem is, if block D is something that simply comes after block C, then what is to stop someone from thinking that if an exception happens, the exception handler runs, then block C… and then block D, because the diagram shows the flow going from block C to block D.
My problem is that the UML spec says specifically “the successorS of the protected node” – plural.
Thanks for replying. As UML is not specific design for modeling specific programming language, I think we can tread it as a common understanding that the flow will be going to Block C and then back to Block B for the return statement, and skip the Block D when exception found.